Introduction à l'ontologie du CSÉC
Cette page web a été traduite automatiquement par DeepL. Bien que nous nous efforcions d’être précis, nous vous informons que les traductions peuvent contenir des erreurs ou des inexactitudes. Pour obtenir les informations les plus précises, veuillez vous référer à la version original.
Résumé
L'Ontologie du Collaboratoire scientifique des écrits du Canada (cséc.ca) regroupe diverses ressources de webs de données produites par le Collaboratoire relatif aux écrivains, à l'écriture et à la culture.
1. Introduction
Même si elle contient des éléments assez généraux pour des activités comme l'annotation et la citation, l'ontologie du CWRC a pour objectif de décrire et relier certains aspects de la Littérature et de l'histoire littéraire en faisant tout particulièrement attention aux questions de genre et à l'interprétation intersectionelle, du fait de ses liens avec Le Projet Orlando, une histoire littéraire des femmes de lettres britanniques. L'ontologie renvoie à un certain nombre de standards tout en s'efforçant de rendre la complexité de la relation entre représentation et provenance dans la production de webs de données et de transmettre la position culturelle et politique (Haraway, 1988) des connaissances représentées.
Certains des documents associés à cette ontologie sont nés d'activités menées au sein du Collaboratoire. D'autres sont générés par un processus de traduction de balises XML intégrées. En d'autres termes, certains sont issus d'activités humaines telles que la création ou la conservation de contenus, alors que d'autres sont générés par machine.
2. À propos de ce document
Ce document est une version de l'ontologie lisible par l'utilisateur qui ne peut pas documenter toutes ses structures de données. L'ontologie elle-même devrait servir de source principale à la compréhension de son fonctionnement.
Ce document est destiné au public académique qui souhaite comprendre la façon dont l'ontologie traite les problèmes concrets relatifs à l’enregistrement de données et aux professionnels des webs de données qui souhaitent utiliser l'ontologie.
3. Statut de l'ontologie dynamique
Ce document et l'ontologie associée sont développés de façon itérative et des modifications y seront apportées au fil du temps à mesure que les données sont progressivement traduites et que de nouveaux problèmes ontologiques sont identifiés. L'utilisation des annotations d'ontologies OWL pour la compatibilité ontologique ainsi que les classes et propriétés obsolètes assure sa continuité. Les termes supprimés de l'ontologie restent présents mais sont signalés comme tels.
L'ontologie est comprise comme un document évolutif qui ne prétend pas à l’exhaustivité. En particulier, les instances sont dérivées de jeux de données spécifiques et seront développées progressivement. Nous acceptons les suggestions de nouvelles classes, de propriétés et de prédicats de la part des personnes souhaitant utiliser l'ontologie pour leurs propres jeux de données, ainsi que des suggestions sur les termes de vocabulaires complexes déjà existants.
Les suggestions de nouvelles classes, propriétés et prédicats de la part de ceux qui souhaitent utiliser l'ontologie pour leurs propres ensembles de données sont les bienvenues, de même que les suggestions relatives à la complexité des vocabulaires associés aux termes existants. Veuillez soumettre vos suggestions par le biais d'un problème ou d'une demande d'extraction dans le Dépôt de code de l'ontologie du CWRC.
4. Contexte des données source d'Orlando
Créé en 1995, le projet Orlando est une histoire littéraire des femmes de lettres britanniques de leurs origines jusqu'à nos jours(Brown, Clements and Grundy, 2007a;Brown, Clements and Grundy, 2007b).
Cette collaboration née-numérique a élaboré une représentation des connaissances (Brown, Clements et al., 2006)sous la forme d'un jeu d’étiquettes SGML conçu sur mesure afin d'encoder le texte avec des priorités et des concepts à mesure qu'il était écrit. Cet ensemble d’étiquettes structure le contenu biocritique, chronologique et bibliographique d'une histoire littéraire contenant plus de huit millions de mots et deux millions d’étiquettes. Le schéma sert de base au Collaboratoire scientifique des écrits du Canada pour des contenus similaires et fournit les fondations de la présente ontologie. La production de certaines des données sources est réalisée par extraction de balises XML incorporées dans les matériaux du Projet Orlando et du contenu de structures similaires présentes au sein du Collaboratoire (Simpson and Brown, 2013).
Orlando: une histoire littéraire des femmes de lettres britanniques des débuts jusqu’à nos jours (Brown and Clements and et al., 2006) est publié par Cambridge University Press.
L'introduction académique et l'introduction à l'ensemble des étiquettes d'Orlando sont disponibles ici: Introduction au jeu d'étiquettes d'Orlando.
La liste des contributeur·ice·s d'Orlando est ici: Contributeur·ice·s d'Orlando.
Les schémas XML du Projet Orlando et le schéma XML du projet de CSÉC sont disponibles ici Github.
5. Objectifs ontologiques fondamentaux
a. Principes
Le schéma recouvre les entités, les classes et les relations associées aux domaines de la littérature et de l'histoire littéraire, interprétées dans une perspective féministe intersectionnelle. La conception de l'ontologie répond aux défis posés par le passage de données semi-structurées à des données structurées (Smith, 2013). Bien que les triplets de données liées soient autonomes sur la forme, beaucoup sont dérivés de prose discursive et sont mieux compris lorsqu’ils sont rattachés à leur contexte d’origine. L’ontologie du CSÉC est conçue pour éviter de présenter les extractions RDF des données d'Orlando comme des assertions positivistes, mais produit néanmoins des schémas de structures compatibles OWL/RDF lisible par une machine. Elle permet de faire référence à, sans les adopter, d’autres vocabulaires ontologiques externes sans qui restent des sources d’information utiles à la documentation des processus culturelles et identitaires.
b. Questions de compétences
Les questions de compétences servent à donner une idée de la portée d'une ontologie et remplissent plusieurs objectifs, notamment celui de donner aux utilisateur·ice·s un aperçu du type d'information qu'il est possible de trouver dans les jeux de données de l'ontologie, et de fournir aux développeurs des critères pour mesurer la qualité de celle-ci. L'ontologie du CSÉC représente un large éventail d'informations sur la biographie, la vie littéraire et les œuvres de ses auteures. De plus, comme pour d'autres données relatives aux sciences humaines, ces informations offrent un large éventail d'utilisation possibles, dont beaucoup ne peuvent pas être définies à l'avance. Par exemple, les romans de Susanna Moodie au dix-neuvième siècle ont été consultés par des chercheur·euse·s en changement climatique. Cette liste de questions n'est donc pas exhaustive, mais devrait donner un aperçu de l'éventail de questions auxquelles l'ontologie peut répondre. Nous soulignons également que les jeux de données représentés par cette ontologie ne sont pas exhaustifs: l'irrégularité des dossiers publiés et archivés ainsi que les méthodes nécessairement sélectives et hiérarchisées selon lesquelles l'information a été collectée et enregistrée impliquent que toute interprétation statistique ou toute représentation liée au type de données pour lequel cette ontologie est conçue doivent être fortement nuancées et contextualisées.
Questions biographiques
- Quelles personnes ont été scolarisées dans telle ville durant une période donnée?
- Quelles auteures britanniques ont fréquenté les mêmes écoles?
- Quel·les auteur·e·s ont été scolarisé·e·s ou ont étudié aux côtés d'une autre femme de lettres?
- Pour qui a-t-on recueilli telle cause de décès précise durant une période donnée?
- Qui faisaient partie de la famille de cette personne? Quels étaient leurs liens de parenté?
- Quel·le·s auteure·s queer/lesbiennes ont été ont fréquenté un établissement non mixte?
Formation culturelle
- Quelles personnes ont été identifiées à telle race, telle couleur de peau ou telle nationalité particulière?
- Quelles femmes de la période victorienne étaient associées à plusieurs nationalités?
- Quel·les auteur·e·s s'associaient à telle forme de judéité de la même façon?
- Quel·les auteur·e·s britanniques étaient à la fois associé·e·s au protestantisme et au catholicisme au dix-neuvième siècle?
- Quels textes littéraires évoquent telle religion ou dénomination religieuse particulière?
- Dans ce jeu de données, quelle est la répartition entre entre les genres féminin et masculin pour les romans publiés durant une période donnée?
- Quel·les auteur·e·s sont associé·e·s à ce groupe politique particulier?
- Associe-t-on davantage les auteur·e·s à des causes relevant des questions de genre à certains moments particuliers de l'Histoire?
Relations personnelles
- Un lien existe-t-il entre deux personnes en particulier?
- À quel point ces deux personnes étaient-elles proches? Est-ce un fait récurrent dans les données, ou est-ce au contraire une occurrence n'apparaissant qu'une ou deux fois?
- Quels sont les types de relations qu’une personne particulière possède avec d’autres individus?
- Quels sont ses liens de parenté?
- Si deux personnes ne possèdent aucun lien direct, quel est le chemin le plus court pour les relier via leurs relations avec d’autres personnes ou d'autres entités comme des organisations ou des textes?
- Quels liens existent-ils entre un ensemble de personnes au cours durant une période donnée?
- Combien de personnes citent tel·le auteur·e particulier·ère en tant que source d’influence sur leur propre travail?
- Combien d'auteur·e·s appartiennent à une organisation particulière? Plus précisément, quelles organisations féministes ont été soutenues par deux ou plusieurs générations d'auteur·e·s de la même famille?
- Qui sont les personnes avec qui cet auteur·e a collaboré professionnellement (relations d’éditeur·ice à écrivain·e, d’auteur·e à d’auteur·e, d’éditeur·ice à d’éditeur·ice, etc)?
- Qui avait un parent dans le milieu de l'édition?
Groupes/réseaux de personnes
- Quels auteur·e·s sont le plus interconnecté·e·s avec d'autres en termes d’influences? 2 Pouvons-nous identifier des groupes d'écrivain·e·s qui semblent évoluer en communauté du fait d’un réseau étroit d'amitiés, de relations littéraires, de publications chez les mêmes éditeurs, de révisions des œuvres de chacun·e, etc?
- Pouvons-nous identifier les individus qui étaient des points de liaison clés entre différents groupes?
- Qui a été influencé·e par des écrivain·e·s de couleur britanniques et/ou internationaux?
- Qui était impliqué·e à la fois dans des groupes féministes et dans l'activisme pour le droit des animaux?
- Qui était en relation avec des groupes artistiques non littéraires?
Questions sur les textes/les œuvres
- Quels livres on été importants dans l'éducation de cet·te auteur·e?
- Quelles sont les critiques sur ce livre en particulier?
- Dans quelles langues cette œuvre spécifique a-t-elle été publiée?
- Y a-t-il une relation intertextuelle reconnue entre X et Y?
- Dans quelles revues apparaît le travail d'un·e auteur spécifique?
- Combien de relations intertextuelles un·e auteur·e possède-t-il·elle avec des œuvres littéraires écrites par des femmes?
- Trouvez toutes les réponses à ce livre qui sont considérées comme genrées.
- Quelles œuvres ont été le plus traduites?
- Trouvez des thèmes et des sujets particuliers dans des textes, par exemple quelles sont les œuvres de fiction contenant des descriptions d’écoles de filles? Quels sont celles qui dépeignent des organisations politiques
- Quel·les auteur·e·s ont écrit pour la même revue à la même période?
- Quelles œuvres de fiction font allusion à une forme d'activisme particulière?
- Y a-t-il des références à des œuvres de fiction dans le travail non-fictionnel de cet·te auteur·e?
- Quelles œuvres de fiction européennes se déroulent en dehors d’Europe?
- Qui a détruit ses propres œuvres? Quelles œuvres ont été détruites par d’autres?
- Quelles écrits semblent avoir été influencés par certaines théories ou philosophies?
Questions géographiques
- Quels textes ont été ou n'ont pas été publiés dans tel pays particulier?
- Quels textes ont fait ou n'ont pas fait l’objet de critiques dans tel pays particulier?
- Dans quelles villes ou pays un·e auteur·e particulier·ère a-t-il·elle résidé?
- Quelles villes ou pays sont décrits ou traités chez cet·te auteur·e?
- Dans quels lieux une œuvre dramatique particulière a-t-elle été jouée?
- Quelles œuvres ont été écrites au cours de voyages?
- Quels textes ont été publiés ou partagés en dehors d’Europe? Quels textes ont été commentés hors d'Europe?
Questions liées au temps et aux évènements
- Dans ce jeu de données, de quels textes parle-t-on le plus durant cette période particulière?
- Retracez la portée d'un texte particulier dans le temps et l'espace.
- Quelle hausse ou quel déclin relatif la réputation d'un·e écrivain·e a-t-elle connu(e) au fil du temps par rapport à d’autres écrivain·e·s de sa période?
- Quels événements de la vie de cette personne on été liés à des aspects de son identité sociale telles que la religion, la classe sociale ou l'appartenance politique?
- Quelle évolution au cours du temps les données montrent-elles pour différentes formes de relations entre plusieurs écrivain·e·s? Par exemple, ce jeu de données enregistre-t-il relativement plus d'intertextualité avec des hommes écrivains ou bien des femmes écrivaines à des moments distincts?
- Quels évolutions et évènements sociaux ou historiques majeurs sont reflétés dans les archives littéraires?
- Pouvons-nous cibler l'exploration des données sur des périodes temporelles particulières, telle que la période victorienne?
- Quel·les auteur·e·s sont susceptibles de se connaître, en raison de chevauchements chronologiques et/ou géographiques, ou du fait d'autres points en commun?
Questions complexes
Dans de nombreux cas, l'ontologie aura un rôle à jouer dans le développement d'une question plus complexe ou dans le cadre d'une démarche herméneutique plus large. Par exemple:
1, Comparez les tendances de publication de ces auteur·e·s, en fonction de leur genre et du nombre de leurs enfants. Leur taux de productivité littéraire augmente-t-il ou diminue-t-il au fil du temps en fonction du nombre d'enfants qu'ils·elles ont? 2. Montrez tous les éléments de l’apprentissage en autodidacte et de l’éducation formelle (livres, disciplines, instructeur·ice·s) mentionnés dans les œuvres d'une auteure. 3. Retracez l'influence d’un phénomène littéraire, tels que l'émergence d'un thème particulier ou d'une caractéristique formelle, sur une évolution sociale plus large. 4. Testez les affirmations sur la montée des genres ou des mouvements littéraires et voyez à quoi elles ressemblent lorsqu'elles sont infléchies par un jeu de données axé sur l'écriture féminine.
c. Outils et fonctionnalités prévus
Les types d'outils et de fonctionnalités que l’ontologie est destinée à soutenir sont également pertinents pour sa structure. L’ontologie prévoit:
- Les recherches avec requêtes SPARQL;
- La navigation, avec la navigation à facettes en fonction de divers critères basés sur l'ontologie, dont les périodes temporelles, les emplacements géographiques ou les propriétés des auteur·e·s;
- Des liens vers nos instances à l'aide de leurs URI;
- La découverte d'informations pertinentes sur les instances via des pages Web déréférenciables;
- La découverte de documents Web qui référencent des instances ou d'autres composants de l'ontologie;
- La visualisation graphique de la structure de l'ontologie, incluant les propriétés et les relations qu'elle contient;
- La visualisation du réseau de relations entre les sujets et d’autres personnes, ainsi que des graphiques d’influences et de relations montrant les liens entre les personnes et d'autres entités comm les livres, capables d’indiquer la directionalité des relations le cas échéant.
- La cartographie des composants de données associées à des indications géospatiales;
- Des chronologies des composants de données associées à des indications temporelles;
- L’utilisation des règles SHACL et d'autres outils d'inférence logique pour vérifier les erreurs de données, les omissions et les incohérences;
- L’utilisation des règles SHACL et d'autres outils d'inférence pour dériver de nouvelles informations à partir de la combinaison de données existantes et des ontologies;
- L’affichage de l’irrégularité des jeux de données par le suivi des sources, de la provenance et des degrés de certitude afin de fournir un aperçu des lacunes du corpus de connaissances;
- L’affichage des conflits, des contradictions et des anomalies dans les jeux de données pour servir de base à la recherche.
d. Liens vers d'autres ontologies
Nous employons plusieurs stratégies afin de nous relier à d'autres ontologies. Notre architecture n’importe pas intégralement d'ontologies tierces, mais renvoie à d'autres vocabulaires larges de façon précise. Nous nous efforçons de ne pas abuser du prédicat sameAs(Halpin, Hayes et al., 2010).
Nous adoptons des espaces de noms, des classes et des termes associés dans la mesure du possible lorsqu'ils sont couramment employés et que leurs vocabulaires sont majoritairement compatibles avec le nôtre, comme c'est le cas du FOAF et du BIBO. Pour certains termes, tels que les dénominations religieuses ou les genres littéraires, nous nous appuyons volontiers, en partie ou en totalité, sur les termes et définitions d'autres vocabulaires comme dans le cas du Getty Art and Architecture Thesaurus (Getty Research Institute). D'autres termes sont référencés avec du recul critique. Ceci s’applique plus particulièrement au vocabulaire en lien avec la classe Forme Culturelle, qui, comme nous l'expliquons plus en détail ci-dessous, sont considérés avant tout comme représentatifs et liés, lorsqu'il existe plusieurs termes apparentés dans l'ontologie, aux termes typés en tant que textual labels. Grâce à cette structure, notre vocabulaire positionne tous les termes associés aux processus de la forme culturelle comme des étiquettes discursives, conservant l'ambiguïté des termes impliqués dans la construction sociale complexe des identités au sein d'un récit. Les formes culturelles peuvent à leur tour être liées à des ontologies externes de plusieurs façons. Si un terme de l'ontologie externe s'aligne sémantiquement sur le nôtre, nous utilisons des relations basées sur OWL ou SKOS telles que <owl:equivalentClass>, <skos:narrower> ou <skos:broader>. Si la définition ou l'utilisation d'un terme externe ne correspond pas à un terme de l'ontologie du CCRF mais que son application dans des ensembles de données externes est telle qu'il sera néanmoins utile de lier ces termes aux nôtres (par exemple pour élargir les recherches à l'aide de la problématique ISO5218 Codes pour la représentation des sexes humains), puis le has functional relation est employé pour indiquer que la relation est spécifiée sémantiquement mais qu'elle peut être exploitée pour le traitement.
Au niveau supérieur, l'ontologie du CSÉC utilise des ontologies bien connues:
- L'ontologie FOAF pour la représentation des personnes et des organisations.
- L'ontologie BIBO pour la représentation des données bibliographiques
- L'ontologie TIME pour la représentation des événements et des moments données pour lesquels les schémas de temps ISO8601 / XML ne sont pas appropriés.
- L'ontologie NIF-CORE est utilisée pour contenir et manipuler le texte des entrées originelles d'Orlando.
- L'ontologie Web Open Annotation st utilisé pour lier le texte source d’Orlando à des Contexts spécifiques.
- Le vocabulaire SKOS est utilisé pour représenter les relations taxonomiques entre certaines Formes Culturelles et des termes de l'ontologie complète.
- Certains termes du vocabulaire Dublin Core sont utilisés pour des étiquettes de documentation reconnues telles que < dc:title >.
- L'ontologie W3C Provenance ontology est utilisé pour indiquer l'origine, la dérivation ou la provenance des termes descriptifs ainsi que les annotations sources des Contextes Culturels.
- Des liens sont faits avec l'ontologie CIDOC-CRM pour les instances culturelles en commun avec le CSÉC.
Certains vocabulaires reconnus comme EuroVoc, les vocabulaires Getty ou ceux de la Librairie du Congrès pour les langues et les GeoNames sont utilisés dans les définitions de nombreuses classes et instances. Par exemple, les termes religieux du vocabulaire Getty Art and Architecture Thesaurus ont fourni des définitions adéquates pour beaucoup de religions, aussi bien que DBPedia et d’autres sources érudites. Des guillemets ponctuent le texte des définitions dont le texte descriptif est repris dans son intégralité. Les termes qui apparaissent entre guillemets sont définis par l'équipe du CSÉC mais peuvent contenir des liens vers des ressources externes telles que des articles académiques ou des entrées DBpedia étroitement liées.
Dans d'autres cas, des termes provenant d'ontologies externes sont adoptés dans les ensembles de données du CCRF sans avoir été importés dans notre ontologie. Voici une liste non exhaustive de ces vocabulaires et des classes pour lesquelles ils sont le plus souvent utilisés:
- Geonames sont souvent utilisés pour désigner des lieux et de nombreux exemples de patrimoine géographique.
- Bibliothèque du Congrès Langues sont généralement utilisés pour les cas de langue.
e. Provenance et contextes
Comme indiqué plus haut, certaines données associées à cette ontologie ont été générées à partir de structures XML (Simpson and Brown, 2013). La provenance est donc particulièrement importante car que les données n'ont pas été originairement produites en RDF, mais sous la forme de balises intégrées dans un contexte discursif. Dans de tels cas, les parties pertinentes du texte sont fournies sous forme d'extratis et deviennent au sein du jeu de données des instances de notes contextuelles ou des annotations lisibles par l’utilisateur et auxquelles les noeuds du jeu de données sont directement liées.
Il était prévu que l’importation massive de vocabulaires complets au sein de l'ontologie du CSÉC causât des problèmes logiques et ontologiques. Pour y remédier, nous avons décidé de ne pas utiliser la structure <owl:import>, mais au lieu de cela associer des vocabulaires externes ou de cloner les groupes de termes spécifiques d’autres vocabulaires présélectionnés. De même, tous les vocabulaires ne sont pas clairement définis d’un point de vue ontologique, mais il s'est avéré utile de s’inspirer de leur prose ou de certaines de leurs propriétés. Pour ce faire, nous avons évité l'utilisation de <owl:sameAs> pour ne pas inclure des propriétés ou des structures ontologiques non voulues au sein du CSÉC. Dans d'autres cas, la propriété ontologique <prov:wasDerivedFrom> est utilisée pour indiquer qu’un terme est construit d’après les informations d’autres termes sans forcément leur être équivalent. Les liens directs vers d'autres ontologies sont généralement effectués par l'utilisation de sous-classes ou de <owl:equivalentClass>.
f. Étiquettes
Pour l'étiquetage, le CWRC utilise deux moyens de promouvoir la facilité de recherche. rdfs:label représente la nomenclature lisible par l'homme pour un concept, une instance ou un prédicat. Il s'agit de la terminologie utilisée pour représenter les composants de l'ontologie dans la documentation et les diagrammes, sauf lorsqu'un URI est fourni.
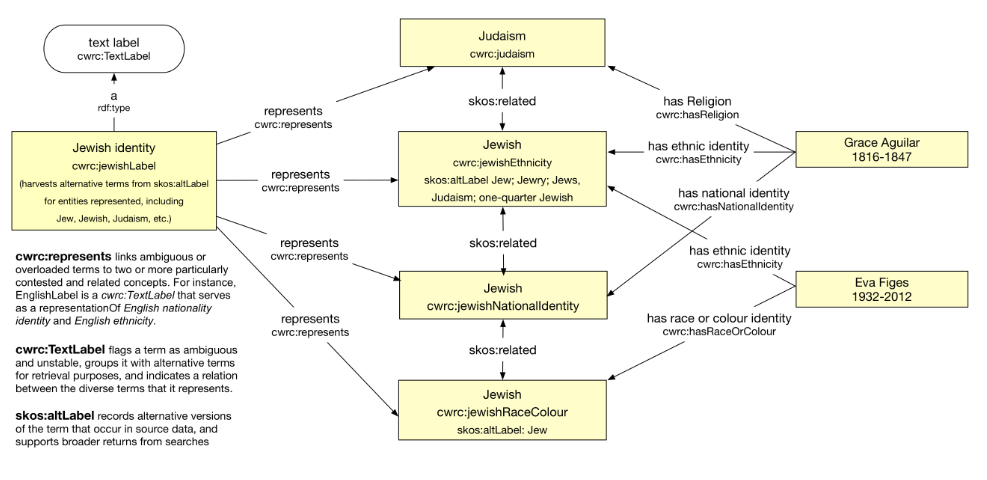
Comme nous l'avons indiqué plus haut à propos de la forme culturelle, lorsque l'étiquette textuelle est utilisé pour typer une classe, il s'agit d'une indication de la représentativité ou de la discursivité de cette classe. cwrc:TextLabels sont fréquemment utilisés pour des termes ambivalents, qui se chevauchent et qui sont culturellement contestés.
En outre, pour aider ceux qui connaissent des ensembles de données antérieurs dont les chaînes ou les termes ont été liés à des fins d'extraction aux termes du CCRF, l'ontologie fournit un contexte linguistique supplémentaire pour les termes de l'ontologie du CCRF. Des étiquettes alternatives, signifiées par skos:altLabel, indiquent des termes provenant d'ensembles de données sources qui ont été utilisés pour créer des relations avec ce concept. Les étiquettes alternatives ne peuvent généralement pas remplacer rdfs:label. Dans l'ontologie, ces étiquettes alternatives existent principalement pour la recherche et l'extraction en permettant aux termes de l'ontologie d'être localisés sous un plus grand nombre d'étiquettes. Bien que certains reflètent les particularités des données sources, ils peuvent être utiles pour élargir les recherches.
g. Diversité culturelle
La diversité culturelle suscite de plus en plus de débats dans champs des humanités numériques et d’autres disciplines. La collection Debates in Digital Humanities (Gold, 2012; Gold and Klein, 2016) rassemble de nombreux articles qui reflètent l’importance croissante des questions de race, de genre, de diversité culturelle et de différence, et n’est qu’un indicateur parmi d’autres de la préoccupation actuelle pour la diversité. L’ontologie ci-présente cherche à représenter une vision intersectionnelle des catégories identitaires, telles qu’elles sont instanciées les schémas de biographie XML du projet Orlando.
La section Formation Culturelle de l'ontologie reconnaît le processus de catégorisation comme inhérent à l’expérience sociale, tout en nuançant sa terminologie et en contextualisant ses catégories identitaires. Cette section entend la classification sociale comme un produit culturel et un point d’intersection où les discours se superposent et se recoupent. Nous utilisons les catégories comme points de départ pour l’analyse des dynamiques culturelles plutôt que comme des taxonomies figées, car de telles catégories n’ont jamais été stables ni incompatibles entre elles. (Algee-Hewitt, Porter, and Walser, 2016). Pour une explication plus en détails de la notion de formation culturelle, voir Brown et al 2017.
6. Les structures ontologiques du CSÉC
Les données sources du CSÉC recouvrent plusieurs types de données: annotations de textes sources, métadonnées, documents granulaires comme les bibliographies, ainsi que du contenu discursif et explicatif sur des éléments biographiques précis et les phénomènes littéraires. Le web de données du CSÉC représente ces informations comme une série d’assertions la plupart du temps rattachées à des contextes spécifiques.
Si la traçabilité complète et intégrée a toujours été un besoin essentiel des expériences reproductibles, elle a un coût en termes de complexité dans un ensemble de données ouvertes liées, dans la mesure où les requêtes nécessaires pour récupérer les informations de base deviennent difficiles à gérer. À cette fin, l'ontologie du CWRC enregistre des informations selon une conception qui permet de suivre la provenance, la certitude et d'autres composantes complexes des données, mais qui est facile à interroger pour produire des triples simples. Cette conception s'appuie fortement sur l'ontologie Modèle de données d'annotation Web.L'annotation Web prend en charge des formes d'annotation assez standard, telles que l'identification des entités nommées dans un texte ou la fourniture d'un mot-clé ou d'une correction, reliant les entités à la source associée d'une manière qui favorise la provenance.
CSÉC also builds on the Web Annotation structure to carry properties associated with those entities through a series of Contextes,typés selon un certain nombre de classes de haut niveau telles que EducationContext, CulturalFormContext, et OccupationContext. Les propriétés associées aux entités pour chaque contexte ont des versions parallèles centrées sur le sujet, qui prennent en charge l'utilisation des commandes SPARQL Construct pour dériver des triplets centrés sur l'entité qui relient simplement les individus à leurs attributs personnels. De cette manière, un suivi approfondi de la provenance est possible, tandis que la production de vues granulaires sujet-prédicat-objet des données est prise en charge par la structure de l'ontologie. Les contextes relient donc un fragment de texte source aux individus ou aux entités auxquels il fait référence, aux propriétés ou aux assertions situées dans ce contexte et à la classe d'expérience ou d'activité à laquelle il appartient.
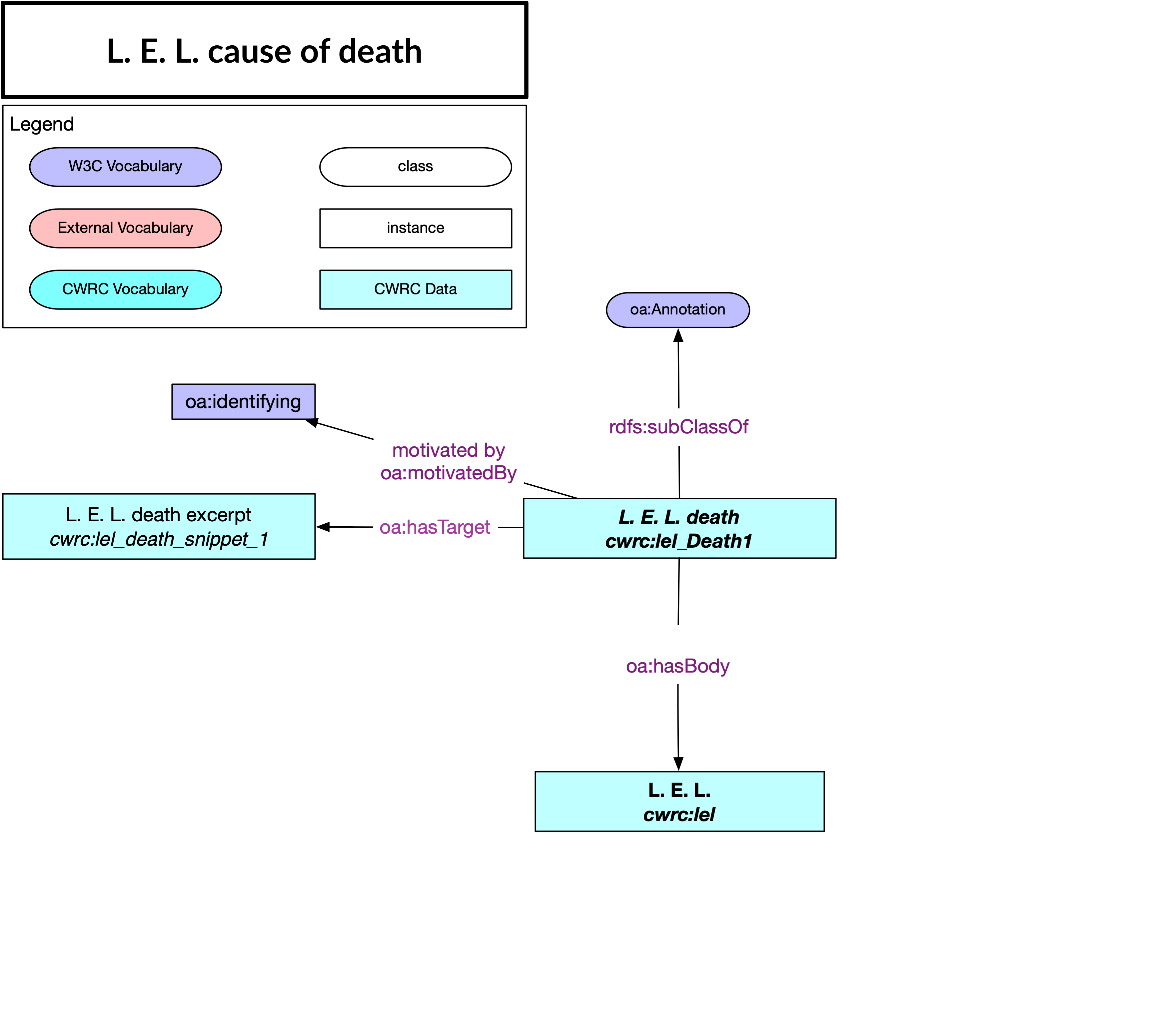
a. Identification des annotations
La plupart des données liées au CSÉC impliqueront l'identification d'entités nommées dans les documents du CSÉC, ce qui constitue un cas d'utilisation simple pour l'annotation Web. Voici un diagramme d'une annotation Web identifiant l'entité personne L.E.L. (Letitia Elizabeth Landon) dans un extrait de la base de données textuelles publiée par le projet Orlando.
b. Contextes (description des annotations)
La classe Contexte utilise les annotations Web pour fournir le contexte discursif des assertions interprétatives dans l'ontologie. Lorsque les assertions ont été générées à partir d'un texte source accessible sur le web, un contexte fournit le texte, ou l'extrait pertinent d'un texte plus long, dont elles ont été extraites. Les contextes permettent d'ancrer les données dans leur source, ce qui peut donner aux utilisateurs une idée de la nuance et de la complexité des assertions liées à des sujets humains et à des phénomènes culturels.
Les contextes sont classés par grandes catégories sémantiques, notamment, pour le matériel biographique, Formes culturelles, Naissance, Mort, Éducation, Profession et Politique, et, pour le contenu littéraire, Production, Réception et Caractéristiques textuelles.
Les principales classes de contexte sont les suivantes:
BiographyContext, BirthContext, CulturalFormContext, DeathContext, EconomicContext, EducationContext, FamilyContext, FriendsAndAssociatesContext, HealthContext, IntimateRelationshipContext, LeisureContext, NameContext, OccupationContext, SpatialContext, et ViolenceContext.
Les contextes du CSÉC s'appuient sur la structure des annotations Web, en classant les annotations par contexte. Alors que les annotations d'identification sont utilisées pour indiquer la présence d'entités particulières, nous déplaçons la motivation de l'annotation vers la description lorsqu'il s'agit de propriétés telles que la cause du décès, puisque ces annotations décrivent ce que dit Orlando, tout en s'engageant elles-mêmes dans la description.
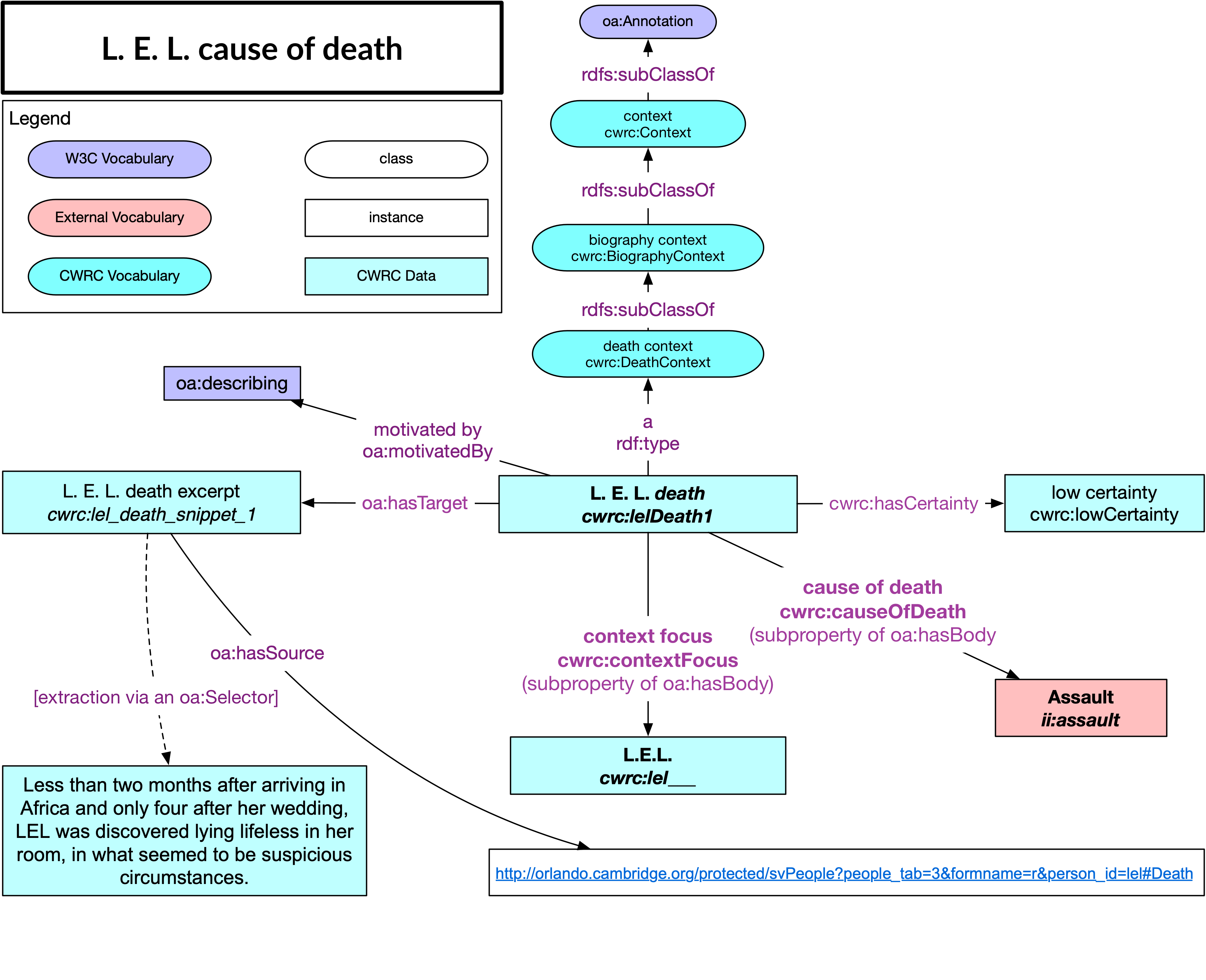
Annotation Web incorporant L.E.L. cause du texte par l'annotation Web triples centrés sur le contexte
La relation entre L.E.L. et sa cause de décès est présente ici, mais d'une manière "centrée sur le contexte" plutôt que sur le sujet. Ce que nous considérons intuitivement comme le "sujet" du triple motif de décès, à savoir L.E.L., est présent, mais il s'agit structurellement d'un objet: L.E.L., cependant, a une relation spéciale, définie par le CWRC, avec l'annotation en tant que "contextFocus", c'est-à-dire le sujet de ce contexte particulier. La propriété "contextFocus", comme d'autres propriétés définies par le CWRC et liées aux annotations, devient une sous-propriété de la propriété standard oa:hasBody. Les liens vers les documents sources à partir desquels le RDF a été extrait sont présents, tout comme la certitude, les liens de citation (non montrés ici), et potentiellement d'autres informations sur cette assertion complexe. Ce graphique n'est pas aussi intuitivement lisible par l'homme, mais il nous permet de conserver des informations contextuelles clés que nous considérons comme essentielles à la création de LODsets robustes pour les sciences humaines.
Le modèle centré sur le contexte permet de créer des triplets centrés sur le sujet, mais ces derniers doivent être générés à partir des données sources au moyen de requêtes SPARQL Construct. L'ontologie du CWRC fournit des versions des prédicats centrées sur le contexte et sur le sujet (par exemple, causeOfDeath et hasCauseOfDeath, respectivement), de sorte qu'il est possible de créer un ensemble de données dérivées à l'aide d'un script par lots pour ceux qui souhaitent voir des relations plus directes, ou à l'aide des commandes SPARQL Construct lors de l'exécution des requêtes.
En outre, la relation entre deux assertions contextualisées différentes permet de traiter des données contradictoires grâce à une relation OR qui permet aux deux contextes d'exister même si les deux assertions qui leur sont associées ne peuvent logiquement pas être vraies toutes les deux - comme c'est le cas pour L.E.L. dont la cause du décès est affirmée comme étant à la fois un meurtre et un suicide dans le document source. Dans ce cas, une faible valeur de certitude pourrait être générée sur la base de cette contradiction dans les données. Ce modèle fournit donc un support au raisonnement qui aidera à identifier les inexactitudes dans les données. Il permettra également de mettre en évidence les zones de controverse, les cas limites, les différences entre les ensembles de données et les cas de négation ou de contradiction, non pas comme du bruit ou des saletés à éliminer des données, mais plutôt comme des éléments sur lesquels les chercheurs en sciences humaines veulent souvent se concentrer et qu'ils veulent examiner de plus près.
c. Personnes, personae et rôles
La distinction entre personnes, personae et rôles est un élément révélateur de la complexité des expériences et des relations humaines.
Cette ontologie adopte la définition FOAF au sens large de foaf:person qui peut être appliquée à toute entité considérée comme une personne, y compris les non-humains. Nous distinguons deux sous-classes de Personnes: personne physique ou être humain, et FictionalPerson, car les personnages fictifs sont importants dans les études littéraires. Si un personnage historique qui est une PersonnePhysique est romancé et devient le #Personnage d’un texte de fiction, il·elle devient aussi une Personne Fictive. Toutefois, si un texte fait simplement allusion ou se réfère à une PersonnePhysique, il·elle ne devient pas aussi une PersonneFictive.
Dans certains cas, une Personne sera associée à un Persona.
L'auteur Michael Field illustre l’idée que “l’identité individuelle est une notion importante et complexe que des ontologies conçues de façon adaptée doivent être capables de refléter” (Brown and Simpson 2013). Le persona Michael Field est né de la collaboration artistique et personnelle entre Katherine Harris Bradley et Edith Emma Cooper à la fin du XXème siècle. Même s'il n'était pas une personne physique, Michael Field a joué un rôle important dans la carrière, la vie sociale et les relations personnelles des deux femmes. "Michael Field" ne peut être attribué à une des deux auteures plutôt qu’à une autre, ni être considéré comme un pseudonyme commun. Michael Field est associé à deux personnes physiques à la fois. L’ontologie du CSÉC cherche à saisir des manifestations de l'originalité et de la pluralité des identités. Elle comprend ainsi la classe de personne "persona" pour décrire des entités telles que Michael Field.
On pourrait faire valoir que les personae sont de simples noms de plume ou de scène, tels que "Currer Bell" pour Charlotte Brontë. Cependant, les personae sont plus que des faux noms. Ils·elles influent sur la façon dont les artistes incarnent socialement, symboliquement, intimement ou artistiquement le statut d’auteur·e. Alors que le nom de plume peut être considéré comme une stratégie de publication dans un contexte spécifique, un persona possède une existence propre allant au-delà de sa signature. Un exemple actual est le collectif d'art FASTWÜRMS. Le collectif fonctionne est plus qu’une identité créatrice et n’occupe qu’un seul et unique poste universitaire à l'Université de Guelph.
Un persona est une création originale, souvent inspiré par le contexte biographique, historique et sociologique de son/ses créateur·ice(s). Les personae tels qu'ils sont définis ici ne doivent pas être confondus avec une maladie mentale ou à un trouble dissociatif de l'identité, car ils ne relèvent pas d'une perception déformée ou incontrôlée de la réalité. Le persona est avant tout une entité identitaire capable d'interargir avec le monde extérieur et qui peut parfois être confondue avec une personne physique réelle. Il est incarné et développé par une personne physique, et peut avoir une activité sociale, littéraire, artistique ou politique. Bien que les Personae soient des personnes FOAF, ils sont distincts des personnes fictives et des personnes physiques du CSÉC qui les incarnent, à moins qu'ils ne deviennent objets de fiction.
Tel qu’indiqué dans l’étiquette Persona récemment incorporée au sein du Text Encoding Initiative, les personae ne sont pas non plus des Roles: "Un rôle peut être assumé par différentes personnes lors de diverses occasions, alors qu'un persona est unique à une personne en particulier, même s’il peut ressembler à d'autres individus. De même, lorsqu'un·e acteur·ice assume ou joue le rôle d'une personne historique, il·elle n'acquiert pas de nouveau persona." (http://www.tei-c.org/release/doc/tei-p5-doc/en/html/ND.html#NDPERSE).
Un rôle peut être endossé par des personae ou des personnes physiques, mais un persona ne peut être adopté par quiconque: il est spécifique à une personne physique, ou plus rarement à plusieurs personnes physiques (comme c’est le cas de Field ou du collectif artistique FASTWÜRMS).
Les rôles sont des personnages ou des fonctions assumées lors d’occasions et de situations spécifiques, c'est-à-dire des événements. Les rôles dramatiques, c'est-à-dire les #Personnages d’une œuvre de fiction, sont adoptés par des acteur·ice·s lors de performances particulières. Par analogie, les rôles sociaux sont adoptés par des individus singuliers lors d’occasions ou d’évènements particuliers, qu’ils soient de longue ou de courte durée. Au cours des événements, les agents, les spectateurs et les commentateurs jouent des rôles clés. Les occupations, les professions ou les activités ne sont pas des rôles, bien qu'elles puissent leur être liées, de même que les liens familiaux ou sociaux. Les rôles seront davantage étoffés par rapport à la composante événement de l'ontologie, qui est actuellement en cours de développement.
d. Forme Culturelle
Les classes Forme Culturelle reconnaissent la catégorisation comme intrinsèque à l'expérience sociale, tout en intégrant des variations terminologiques et contextuelles sur les catégories identitaires à travers des instances employées à différents niveaux discursifs.
Les sous-classes et les instances de la forme culturelle décrivent les positions de sujet des individus par le biais de Contextes. Les contextes sont liés à des propriétés granulaires du formulaire culturel qui sont à leur tour associées à la personne qui est l'auteur du formulaire culturel contextFocus de l'annotation. Cela trouve son origine dans l'arrangement Orlando des encodages du formulaire culturel qui oriente les utilisateurs vers un cadre permettant de soulever et de débattre de questions complexes en vue d'une investigation culturelle, plutôt que d'invoquer des catégories réifiées.
Le défi principal du passage de balises sémantiques intégrées au web de données était de rendre cette approche compatible avec le lien vers d'autres ontologies et des jeux de données externes au cadre de référence d'Orlando. Le mouvement "chaînes de texte vers des liens" ou "chaînes vers des choses" contredisait en quelque sorte l’ancienne 'ambiguïté présente dans des chaînes de caractères comme “blanc”, “noir”, “anglais”, et ainsi de suite: “blanc” et “noir” peuvent représenter la race ou l’origine ethnique, et on peut aussi bien utiliser “anglais” pour désigner un individu, une nationalité ou un héritage national. Orlando annote ces chaînes de textes avec son ensemble d’étiquettes Formes Culturelles, par exemple spécifiques au contexte racial ou ethnique, requérant un lien avec l’instance spécifique de Forme Culturelle associée dans le web de données. Ainsi, il existent des instances de Forme Culturelle qui renvoient à l’entité discursive blanc en tant que race et d’autres qui renvoient à blanc en tant qu’ethnie. Enfin, il existe également une étiquette blanc qui peut être instancié aussi bien comme race que comme ethnie, à condition que ce ne soit pas au sein de la même assertion (même si des affirmations multiples sont possibles).
Ce point constitue un écart par rapport aux anciens vocabulaires contrôlés (en données ouvertes non liées), car l'apparence du terme ou de l'étiquette (“blanc” dans ce cas) n'indique pas la formation culturelle spécifique évoquée, mais c’est son instance spécifique qui le fait. Cela signifie également que des liens vers d'autres jeux de données ou d’autres vocabulaires peuvent être réalisés de manière adéquate, puisque des représentations multiples de la même étiquette sont présentes dans l'ontologie du CSÉC. En dernier recours ou dans le cas d’exploration de données, le terme existe aussi comme concept sans Forme Culturelle rattachée à une des différentes options proposées par le CSÉC. Cela permet de lier vers une ontologie externe, tel que cela peut être nécessaire lors de l’exploration de données, sans adopter la définition ou l'interprétation associée du terme. Enfin, les propriétés skos:altLabel fournissent des variantes qui indiquent les termes ou chaînes de vocabulaire non structurés qui ont été traduits dans ces instances de vocabulaire.
i. Propriétés granulaires
Les propriétés granulaires constituent un moyen simple d’indiquer des catégories culturelles telles qu’elles sont perçues, assignées à une personne selon des conventions culturelles, ou autodéclarées par les personnes elles-mêmes. Certaines propriétés sont des associations héritées par des générations précédentes.
La plupart des propriétés prennent la forme de noms, conformément aux conventions des ontologies, mais dans certains cas, l'idiome rend les formes adjectivales préférables, même si ces termes fonctionnent comme des noms, comme dans le cas de l'identité sexuelle celibate.
e. Taxonomies intégrées
i. Religion
Les données originales d'Orlando posent des difficultés pour recenser les religions car ses contextes originaux ne faisaient pas la différence entre croyance religieuse, appartenance à une organisation religieuse et absence de toute croyance combinée à l'observance de valeurs ou de pratiques.
Nous utilisons une taxonomie pour l’énumération de catégories associées à cet éventail de termes. La taxonomie en elle-même s’appuie sur le schéma SKOS et représente un mélange en désordre de croyances partagées et de ramifications historiques.
La taxonomie tente de tracer de façon subjective la lignée théologique et/ou historique du système de croyance. Comme l'application d’étiquettes à un individu, il s'agit d'une démarche d'interprétation.
La taxonomie spécifique est la suivante:
ii. Appartenance politique
Les catégories d'appartenance politique couvrent un large éventail de partis politiques, de mouvements plus ou moins organisés et de causes diverses. Les instances ci-présentes mettent l’accent sur des du contexte politique Britannique qui sont d’intérêt historique pour les femmes, en soulignant que les mouvements tels que le féminisme sont controversés et diffèrent en fonction du contexte géographique et historique. Certaines appartenances sont reliées via des relations SKOS, mais il existe d'autres courants croisant différents groupes qui ne peuvent être inclus ni dans ces relations ni dans les données contextualisées. Comme pour les autres composants de cette ontologie, étant dérivé du jeu de données d'Orlando ce vocabulaire ne prétend pas à l'exhaustivité et pourra être complété si nécessaire.
La taxonomie spécifique est la suivante:
iii. Genre littéraire
L'ontologie distincte Ontologie des genres contient une taxonomie des médias culturels, des formes et des genres, avec un fort accent sur les genres littéraires, basée sur une approche combinée OWL et SKOS Afin de faciliter l'application de termes à des productions culturelles particulières et de permettre leur discussion en tant que concepts, les genres sont des instances au sein de l'ontologie des genres du CSÉC et sont liés à des œuvres culturelles particulières par le biais de la propriété hasgenre.
Étant donné qu'il est utile, pour un certain nombre d'objectifs, de pouvoir passer de genres plus larges à des genres plus spécifiques, l'ontologie organise ses termes en combinant les éléments suivants OWL des classes qui permettent des regroupements larges et des SKOS les relations taxonomiques entre les instances. Les classes OWL permettent de raisonner à partir de termes plus étroits vers des termes plus larges, tandis que les propriétés SKOS offrent des relations transitives plus limitées entre les termes plus étroits et plus larges.
f. Notes sur les ChangeSets
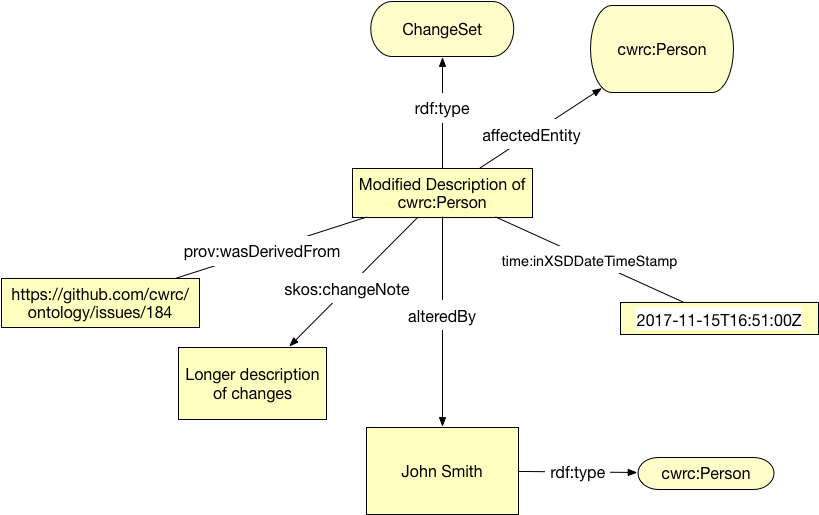
Les ChangeSets existent pour garder trace des modifications apportées aux instances, aux termes et aux classes de l'ontologie. Ils sont donc utilisés par les auteur·e·s de l'ontologie ainsi que par les utilisateur·ice·s qui effectuent des ajouts ou des modifications. Les ChangeSets sont des instances reliées vers ou à partir d'une structure de l'ontologie. Le lien est réalisé via les propriétés d'objet entité modifiée ou via skos:changeNote. Une seule modification ChangeSet peut s'appliquer à plusieurs entités. Par conséquent, la relation cwrc:affectedEntity peut être appliquée 0 fois ou plus. Les ChangeSets répère également l'utilisateur·ice via la relation cwrc:alteredBy qui peut être liée à une cwrc:NaturalPerson. De plus, les dates et les heures sont conservées par le time:inXSDDateTimeStamp et l’utilisation de xsd:dateStamps pour repérer le moment où l’ontologie a été modifiée. Cela permettra d’utiliser les ChangeSets comme des versions et de repérer les changements majeurs effectués à une date précise. Grâce à la provenance, les ChangeSets peuvent être reliés à des ressources externes, ce qui permet de poursuivre toute discussion sortant du cadre de l’ontologie. De brèves discussions peuvent être incluses via la relation skos:changeNote ainsi que par le titre standard rdfs:label. Les ChangeSets doivent être utilisés chaque fois qu'un problème est résolu par des développeur·euse·s d'ontologies ou qu'une instance est modifiée par un·e utilisateur·ice. Des mécanismes automatisés seront utilisés pour compenser certaines des démarches nécessaires.
g. Has Functional Relation
Le prédicat de relation fonctionnelle indique que les deux termes peuvent être traités comme liés pour des fonctions telles que l'interrogation et la recherche, mais il nie également l'existence d'une relation sémantique entre les deux termes. Ce prédicat est conçu pour rassembler des termes incommensurables à des fins de traitement, mais aussi pour les exclure des opérations sémantiques. Il se différencie, par exemple, de la propriété skos:semanticRelation et du prédicat skos:closeMatch qui servent un objectif similaire mais affirment une proximité sémantique.
L'un des objectifs de cette relation est de faciliter les comparaisons et les relations avec d'autres ontologies et vocabulaires avec lesquels les utilisateurs sont plus familiers. L'utilisation de cette relation ne signifie pas que les deux termes ne sont pas liés sémantiquement, mais plutôt que les relations sémantiques actuelles disponibles dans OWL, SKOS et d'autres ontologies utilisées par cette ontologie ne sont pas suffisamment nuancées pour permettre de spécifier une relation sémantique d'une manière qui puisse être traitée de manière appropriée par d'autres outils (tels que les moteurs d'inférence).
7. Règles de conception de l'ontologie de l’ontologie du CSÉC
Au-delà du formalisme du OWL 2 Web Ontology Language, l'ontologie du CSÉC suit les principes de design et les styles suivants:
- Pour le contenu des rdfs: les étiquettes sont toujours en minuscules, aux exceptions près:
- Les étiquettes de religions, d’appartenances politiques et de groupes de personnes dérivées de noms propres prendront une majuscule.
- Dans la mesure du possible, l'équivalent de l’étiquette XML originale d’Orlando est contenue dans la variable
rdf:valuede n'importe quel terme de l'ontologie. - Chaque fois que vous faites référence à une zone géographique, utilisez l'élément le plus précis de la base de données.
- Les définitions en Français et Anglais (ainsi que certaines définitions en d'autres langues) ne sont pas des traductions mot à mot et sont des définitions à part entière.
8. Notes sur les langages SKOS et OWL
Le SKOS (Simple Knowledge Organization System) jouit d'une grande popularité au sein de la communauté du web sémantique, car il fournit des termes simples pour les taxonomies sans exiger la présence d’un agent raisonneur. Chaque fois que cela s'avère approprié, les termes SKOS sont insérés dans cette ontologie pour relier les termes entre eux. Cependant, étant donné que ces termes ne sont pas ontologiquement renseignés, leur capacité d’évolution est limitée car chaque couche de termes supplémentaire dans une taxonomie nécessite une autre requête auprès de la base de données.
Certaines des constructions de l'ontologie du CSÉC sont complexes et requièrent un raisonnement. OWL est le moyen privilégié pour utiliser cette ontologie, bien que l'utilisation des termes, dans le style de ceux de SKOS, soit possible.
9. Conclusion et travail futur
Ce brouillon d’ontologie est un travail en cours. Il continuera d’être développé, étendu et révisé à mesure que nous découvrons ce qu’implique la structure de l’ontologie à travers l’extraction et l'exploration de nos données, puisque de nouvelles informations et divers cas d’utilisation nécessitent un travail d’élargissement ou de précision, et que nous identifions de nouveaux besoins, de nouvelles interprétations et de nouveaux débats.
10. Historique des versions
- 0.99 - Version publique initiale.
- 0.99.2 - Publication périodique avec mise à jour des logos, des genres, de la documentation et des données d'auteur·e·s adéquates.
- 0.99.6 - Publication périodique avec mise à jour du style, des questions de compétences et documentation concernant les événements et les ChangeSets
- 0.99.75 - Publication périodique
- 0.99.80 - Publication périodique avec ajout de professions, de types de diplômes, de titres de formation